Clustering
Clustering Algorithms Comparison
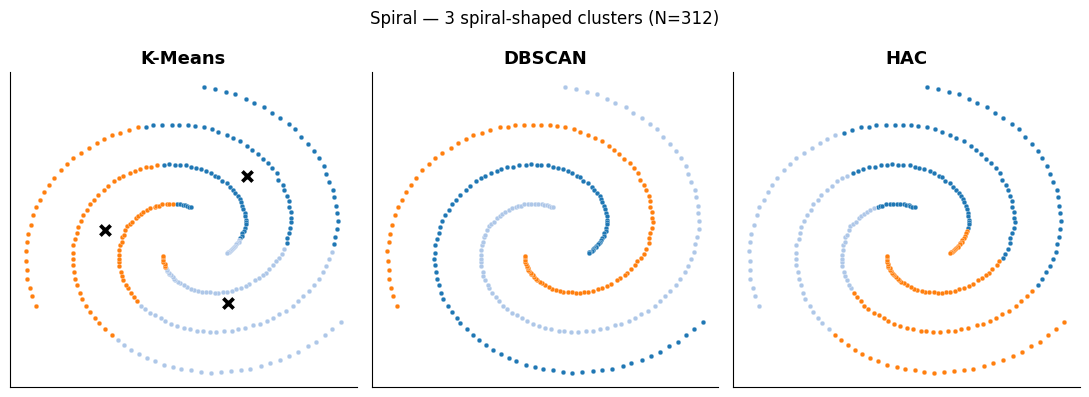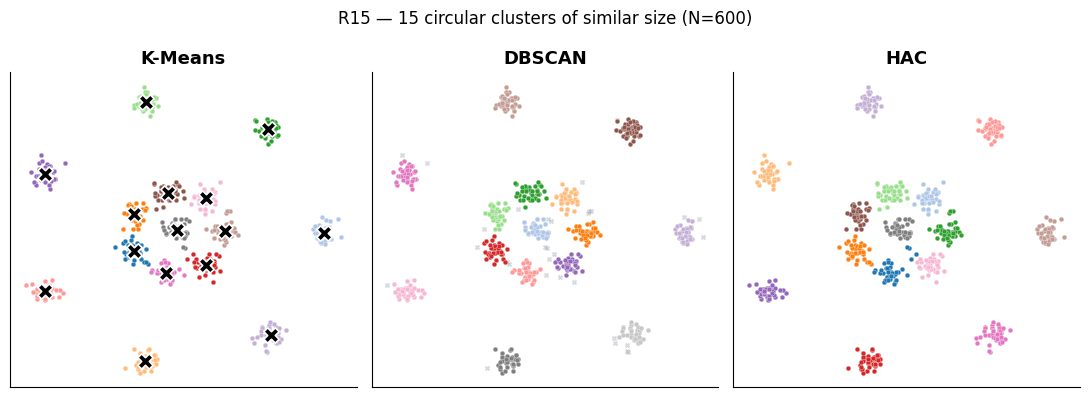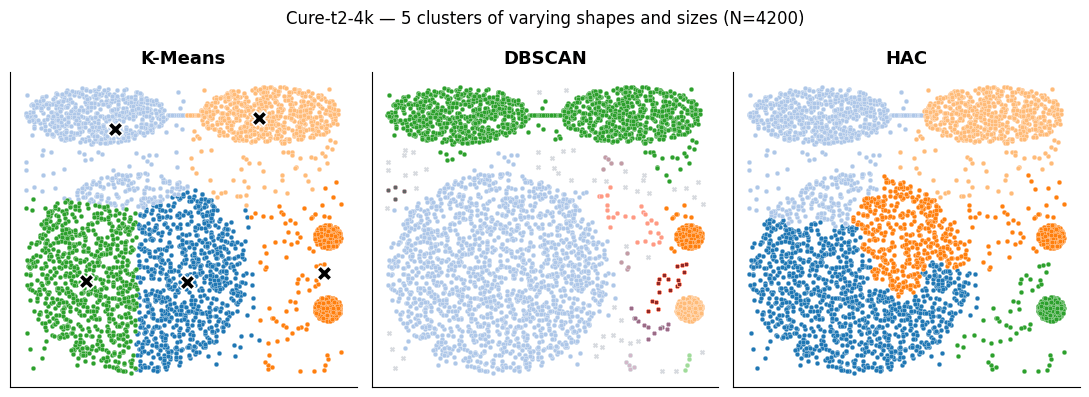
Three clustering algorithms (K-Means, DBSCAN, HAC) tested side-by-side on three different geometries — circular blobs, density-varying clusters, and shapes connected by outliers. The 'best' algorithm depends on the geometry; this demo lets you see how each one fails in different ways.
Try DemoCourse: Pattern Recognition in Data Mining
Objectives
- 1Compare K-means, hierarchical agglomerative clustering and DBSCAN on three different datasets.
- 2Identify advantages and disadvantages of each algorithm.
Conclusions
- K-means recognizes circular clusters of similar size well but fails with different sizes and complex shapes.
- DBSCAN detects clusters of any shape and density but fails when clusters are joined by outliers.
- HAC detects complete shape clusters but is sensitive to outliers that can create bridges between clusters.
Technologies
- Scikit-learn
- FastAPI
- Matplotlib
- NumPy